説明可能AI
深層学習モデルは,画像認識・自然言語処理・意思決定など多くの分野で高い性能を示している一方で,その判断根拠や内部表現はブラックボックスであることが多い.この不透明性は,信頼性・安全性・科学的理解の観点から,本質的な課題となっている.説明可能AI(XAI)は,機械学習モデルの出力や判断過程を,人間が理解可能な形で表現・分析するための研究分野である.
本研究室では,説明可能AI(Explainable AI, XAI)を「モデル内部の知識構造を解析・再構成するための基盤技術」として位置付け,単なる可視化に留まらない,理論的に定義可能で再現性のある説明手法の確立を目指している.
Shapley値および相互作用値を用いた重要な画像領域の特定
本研究では,深層モデルの判断を「個々の特徴の足し合わせ」ではなく,情報同士の相互作用によって形成される知識構造として捉える.この立場から,ゲーム理論におけるShapley値および相互作用に基づく解析手法を導入し,画素やパッチ,概念がどのように協調してモデルの確信度を形成しているかを定量的に評価する.計算量の課題に対しても理論的整理を行い,実用的な計算コストでの説明を可能にしている.これらの研究を通じて,視覚モデルや視覚言語モデルにおける判断の「なぜ」を人間が理解可能な構造として提示することを目標としている.
画像認識モデルへの応用
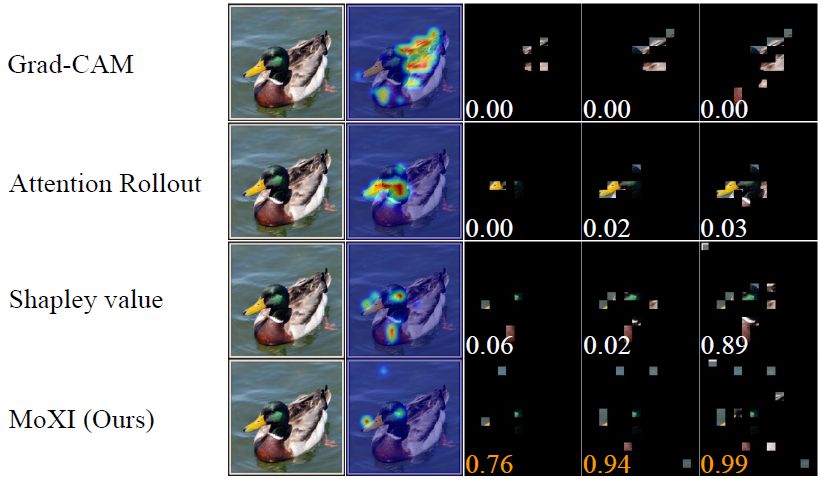
Kosuke Sumiyasu, Kazuhiko Kawamoto, and Hiroshi Kera, Identifying Important Group of Pixels using Interactions, CVPR, pp. 6017-6026, 2024 [paper][arXiv][GitHub].
本論文では,画像分類モデルの判断に強く影響する画素集合を,同時寄与や情報の冗長性を考慮して同定する説明可能AI手法 MoXI を提案する.Shapley値に加えて画素間の相互作用を導入することで,個々の画素の重要度だけでなく,協調的に信頼度を高める画素群を特定可能とした.さらに,自己コンテキスト型の定式化により,計算量を指数時間から二次時間へ削減する.ImageNetを用いた実験により,Grad-CAMやShapley値に比べ,より少ない画素で高い信頼度を説明できることを示した.下図は,提案手法(MOXI)が,既存手法(Grad-CAM,Attention Rollout,Shapley value)と比較して,より少数の画像パッチから,画像認識に寄与する領域を特定できていることを示している.興味深いことに,画像パッチ間の相互作用を考慮することで,この画像では物体(カモ)と背景(湖面)の両方が認識に必要であることがわかる.
物体検出モデルへの応用
Toshinori Yamauchi, Hiroshi Kera, Kazuhiko Kawamoto, Explaining Object Detectors via Collective Contribution of Pixels, arXiv:2412.00666, 2024 [arXiv][GitHub].
本論文は,物体検出モデルの判断を,画素やパッチの個別寄与ではなく,複数画素の集合的寄与(相互作用)として説明する手法 VX-CODE を提案する.従来の可視化手法は,支配的な特徴のみを強調し,物体検出に重要な構成的手掛かりや間接的影響を捉えられないという問題があった.VX-CODEは,ゲーム理論に基づくShapley値と相互作用指標を用いて,画素群が協調して境界ボックス生成およびクラス判定に与える影響を定量化する.指数計算量の問題に対しては,貪欲なパッチ挿入・削除戦略を導入し,実用的な計算コストでの説明を実現した.ImageNetや代表的物体検出器を用いた実験により,既存手法よりも高い忠実性を持つ説明が得られることを示している.下図は,提案手法(VX-CODE)が,既存手法(ODAM,SSGrad-CAM++)と比較して,より少数の画像パッチから,物体検出に寄与する領域を特定できていることを示している.

モデルの内部判断を言語化する説明可能AI
本研究では,「説明とは,画像に写っている内容を単に言語化することではなく,モデルが判断に用いた内部的根拠を明らかにすることである」という立場をとる.すなわち,「何が見えるか」を述べる説明ではなく,「なぜそのクラスと判断したのか」を明らかにする説明を対象とする.人間が理解可能な説明は,モデルの内部表現と整合していなければならないという考えに基づき,本研究では後付けの言語生成に依存せず,内部表現そのものを起点とした説明可能性の確立を目指す.
画像分類モデルに対するゼロショット自然言語説明
Toshinori Yamauchi, Hiroshi Kera, Kazuhiko Kawamoto, Zero-Shot Textual Explanations via Translating Decision-Critical Features, arXiv:2512.07245, 2025 [arXiv].
本論文では,画像分類器の判断理由を自然言語で説明するゼロショット手法TEXTERを提案する.予測に直接寄与した内部特徴を抽出し,概念画像として可視化した上で言語化することで,分類器の判断根拠と整合した説明を生成する.ImageNetおよびPASCAL VOCを用いた実験により,既存手法よりも忠実な説明が得られることを示している.下図は,提案手法TEXTERによって,抽出した概念の可視化およびその自然言語での説明の例を示している.

視覚言語モデルにおけるプロンプト学習の自然言語説明
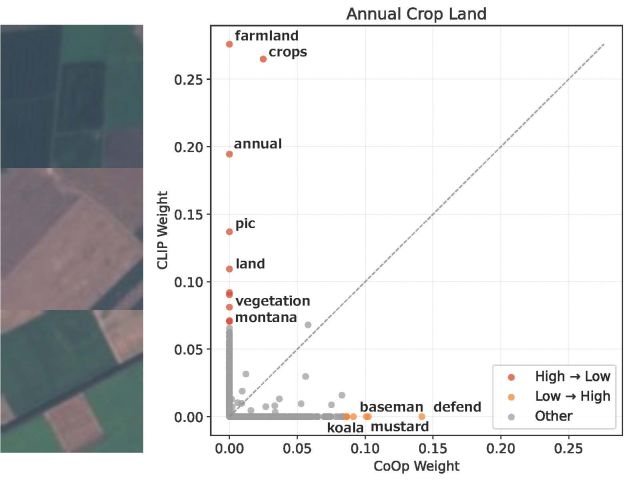
神谷 涼,計良 宥志,川本 一彦,概念分解に基づく視覚言語モデルのプロンプト学習の説明,情報処理学会研究報告CVIM研究会,2026.
本論文では,視覚言語モデルにおけるプロンプト学習のブラックボックス性を解消するため,学習前後のプロンプト埋め込みを自然言語概念の疎な線形結合として分解する手法 PromptSpLiCE を提案する.CoOp を対象とした分析により,プロンプト学習は新たな概念を獲得するのではなく,既存概念の活性度分布を再編成する過程であり,その変化量が分類精度の向上と正に相関することを示した.下図は,EuroSAT データセットの例を用いて,プロンプト学習前後で言語概念がどのように変化するかを示している.