Explainable AI
Deep learning models have achieved remarkable performance in a wide range of domains, including image recognition, natural language processing, and decision-making. However, their decision-making processes and internal representations often remain opaque. This lack of transparency poses fundamental challenges in terms of reliability, safety, and scientific understanding. Explainable AI (XAI) is a research field that aims to represent and analyze the outputs and decision processes of machine learning models in a form that is understandable to humans.
In our laboratory, we regard Explainable AI (XAI) as a foundational technology for analyzing and reconstructing the internal knowledge structures of models. Rather than relying on ad hoc visualizations alone, we aim to establish explanation methods that are theoretically well-defined, reproducible, and capable of providing deeper insight into how models reason and make decisions.
Identifying Important Image Regions Using Shapley Values and Interaction
In this line of research, we view the decisions of deep models not as a simple sum of individual features, but as knowledge structures formed through interactions among multiple pieces of information. From this perspective, we introduce analysis methods based on game-theoretic Shapley values and interaction effects to quantitatively evaluate how pixels, patches, and concepts cooperate to shape a model’s confidence. We also provide a theoretical treatment of the computational complexity and enable practical explanations at a reasonable computational cost. Through these studies, our goal is to present the “why” behind the decisions of vision and vision–language models in a form that is understandable to humans.
Application to Image Recognition Models
Kosuke Sumiyasu, Kazuhiko Kawamoto, and Hiroshi Kera, Identifying Important Group of Pixels using Interactions, CVPR, pp. 6017-6026, 2024 [paper][arXiv][GitHub].
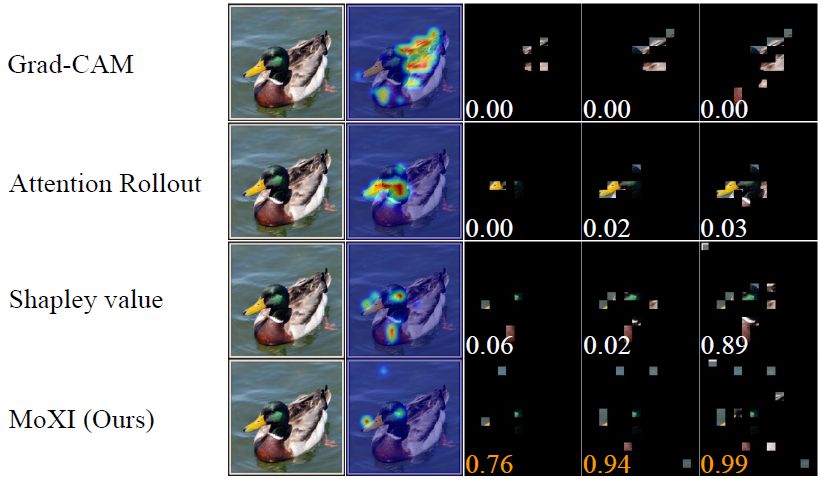
In this paper, we propose MoXI, an explainable AI method that identifies groups of pixels that strongly influence the decisions of image classification models by accounting for joint contributions and information redundancy. By incorporating pixel-wise interactions in addition to Shapley values, MoXI can identify not only individually important pixels but also groups of pixels that collaboratively increase the model’s confidence. Furthermore, a self-context-based formulation reduces the computational complexity from exponential to quadratic time. Experiments on ImageNet demonstrate that MoXI can explain high-confidence predictions using fewer pixels than existing methods such as Grad-CAM and Shapley-value-based approaches. The figure below shows that MoXI is able to localize decision-critical regions using a smaller number of image patches compared to Grad-CAM, Attention Rollout, and Shapley value methods. Interestingly, by modeling interactions between image patches, MoXI reveals that both the object (a duck) and the background (the water surface) are jointly necessary for correct recognition in this example.
Application to Object Detection Models
Toshinori Yamauchi, Hiroshi Kera, Kazuhiko Kawamoto, Explaining Object Detectors via Collective Contribution of Pixels, arXiv:2412.00666, 2024 [arXiv][GitHub].
This paper proposes VX-CODE, a method for explaining object detection models by modeling decisions as the collective contribution of multiple pixels, rather than as independent contributions of individual pixels or patches. Conventional visualization methods tend to highlight only dominant features, and therefore fail to capture compositional cues and indirect influences that are critical for object detection. VX-CODE addresses this limitation by leveraging game-theoretic Shapley values and interaction indices to quantitatively measure how groups of pixels jointly contribute to both bounding box generation and class prediction. To overcome the exponential computational cost inherent in interaction-based explanations, we introduce a greedy patch insertion and removal strategy, enabling explanations at a practical computational cost. Experiments on ImageNet and representative object detectors demonstrate that VX-CODE provides more faithful explanations than existing methods. The figure below shows that VX-CODE can identify regions that contribute to object detection using fewer image patches compared to ODAM and SSGrad-CAM++.

Explainable AI for Verbalizing Internal Model Decisions
In this line of research, we adopt the view that explanation is not simply a verbal description of what appears in an image, but rather the elucidation of the internal evidence used by a model to make its decision. That is, we focus not on explaining what is visible, but on explaining why the model predicted a particular class. Based on the principle that human-understandable explanations must be aligned with a model’s internal representations, our work aims to establish explainability frameworks that start directly from internal representations, rather than relying on post-hoc language generation.
Zero-Shot Natural Language Explanations for Image Classification Models
Toshinori Yamauchi, Hiroshi Kera, Kazuhiko Kawamoto, Zero-Shot Textual Explanations via Translating Decision-Critical Features, arXiv:2512.07245, 2025 [arXiv].
This paper proposes TEXTER, a zero-shot method for explaining the decisions of image classifiers in natural language. TEXTER extracts internal features that directly contribute to a model’s prediction, visualizes them as concept images, and then translates them into textual explanations. By grounding explanations in decision-critical internal features, TEXTER produces descriptions that are faithful to the classifier’s actual reasoning process. Experiments on ImageNet and PASCAL VOC demonstrate that TEXTER provides more faithful explanations than existing methods. The figure below illustrates examples of concept visualizations extracted by TEXTER and their corresponding natural language explanations.
