Video Generation
Video data is becoming increasingly important in many domains, including surveillance, healthcare, entertainment, and human–computer interaction. However, real-world videos are high-dimensional and temporally complex, and collecting large amounts of annotated data is often difficult. Moreover, essential factors such as human actions, facial expressions, and object interactions should be understood not only as pixel-level changes, but as meaningful and structured dynamics. Motivated by this, our research focuses on fundamental questions in video generation: how videos should be decomposed and represented, and how high-quality and flexible video generation can be achieved from limited data. We study generative models that capture the essential structure of videos through the separation of static and dynamic factors, generalization to unseen classes, image-to-video generation, and multimodal generation from visual inputs to sound.
Video Disentanglement
Haga, Takeshi, Hiroshi Kera, and Kazuhiko Kawamoto, Sequential Variational Autoencoder with Adversarial Classifier for Video Disentanglement, Sensors 23, no. 5: 2515, 2023 [paper].
This paper proposes a sequential variational autoencoder that disentangles static and dynamic factors in video data using a two-stream architecture. To overcome the insufficient separation and weak discriminability of dynamic features, a supervised adversarial classifier is introduced as a strong inductive bias. Experiments on the Sprites and MUG datasets show that the proposed method achieves more effective and discriminative video representations.
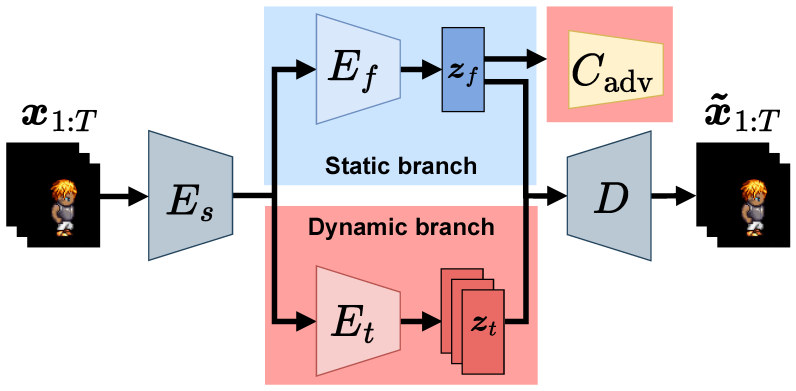
Image Animation via Flow Transfer
Kazuma Kurisaki and Kazuhiko Kawamoto, Animating Cloud Images With Flow Style Transfer, IEEE Access, Vol.9, pp.3269-3277, 2021 [paper][GitHub].
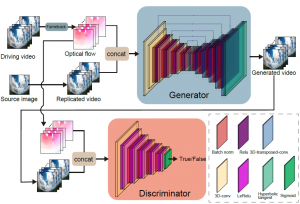
This work proposes a deep learning approach for animating a single static image by transferring motion from a separate video. Motion information is extracted as optical flow and applied to the target image, enabling video generation while preserving the original appearance. By separating image content and motion, the method allows flexible and controllable image-to-video animation.
![]()
Generating Eating Sounds from Food ASMR Videos
Kodai Uchiyama and Kazuhiko Kawamoto, Audio-Visual Model for Generating Eating Sounds Using Food ASMR Videos, IEEE Access, Vol.9, pp.50106-50111, 2021 [paper][GitHub].
This paper proposes an audio–visual model that generates eating sounds from silent food videos. The model takes visual features of the detected face as input and predicts spectrograms that are temporally aligned with the video. Waveforms are reconstructed using the Griffin–Lim algorithm and inverse short-time Fourier transform, combined with an example-based synthesis process for more natural sound generation. Experiments on a dataset of ASMR videos show that the generated sounds are well synchronized with the visuals and perceived as highly realistic in subjective evaluations.
Compositional Zero-Shot Video Generation with Deep Learning
Shun Kimura and Kazuhiko Kawamoto, "Conditional Motion and Content Decomposed GAN for Zero-Short Video Generation," In Proc. of the 7th International Workshop on Advanced Computational Intelligence and Intelligent Informatics, 2021 [arXix].
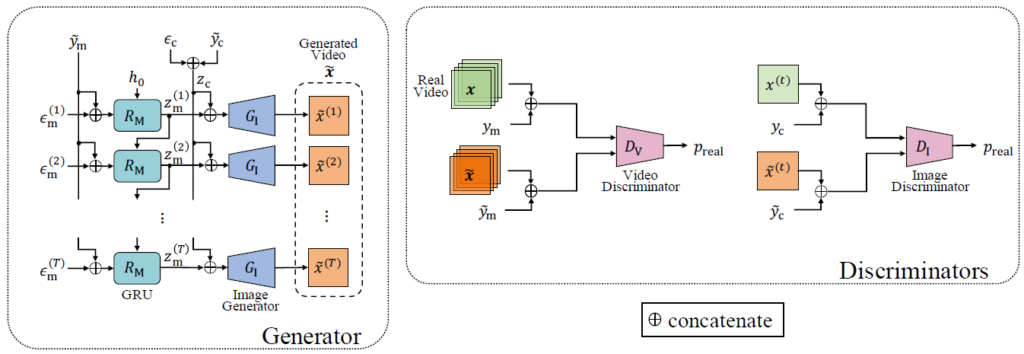
This paper proposes a conditional GAN framework for zero-shot video generation, where videos of unseen classes are generated from training data with missing class combinations. The key idea is to learn disentangled representations of motion and content in the GAN latent space. By decomposing motion and appearance using a conditional GAN architecture, the proposed method enables compositional generalization and high-quality video generation. Experiments on the Weizmann action dataset and the MUG facial expression dataset demonstrate the effectiveness of the approach.

Video Generation with Depth Estimation and Color Transformation using GANs
Y. Nakahira and K. Kawamoto, DCVGAN: Depth Conditional Video Generation, IEEE International Conference on Image Processing (ICIP), pp. 749-753, 2019 [paper][GitHub].
Y. Nakahira and K. Kawamoto, Generative adversarial networks for generating RGB-D videos, Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), pp. 1276-1281, 2018 [paper].
This work proposes a GAN-based video generation framework that leverages depth information in addition to RGB videos. While most existing methods rely only on color information, depth provides important geometric cues for modeling scene dynamics. The proposed architecture first generates depth videos and then transforms them into RGB videos, enabling more accurate motion modeling. Experiments on facial expression and hand gesture datasets show that incorporating depth information improves both the diversity and quality of generated videos compared to conventional approaches.