Action Recognition
Action recognition aims to understand human actions from visual data such as videos and skeletal representations. It is a core technology with broad applications, including human–computer interaction, robotics, surveillance, and medical support. Despite significant progress, action recognition still faces fundamental challenges, such as robustness to environmental changes, generalization to unseen action classes, and the reliability and interpretability of deep learning models.
To address these challenges, our research focuses on integrating multiple modalities, including skeleton data and egocentric video, improving generalization through zero-shot and multitask learning, analyzing robustness via adversarial attacks and frequency-domain analysis, and incorporating human knowledge through language information. Our goal is to establish action recognition models that operate reliably and robustly in real-world environments.
Zero-Shot and Language-Guided Action Recognition
We study zero-shot action recognition, which enables the recognition of action classes that are not observed during training. Many existing approaches rely on frame-level RGB features, making them sensitive to environmental variations and limited in their ability to model temporal dynamics. In contrast, we propose a multi-stream graph convolutional network that integrates RGB video and skeleton data, achieving robust action recognition while explicitly modeling temporal structure.
In addition, we introduce vision–language approaches that describe actions using words or sentences, allowing human knowledge and instructions to guide recognition in zero-shot settings. To further reduce manual effort, we leverage ChatGPT to automatically generate semantic action descriptions. This approach minimizes human intervention while maintaining high recognition performance, demonstrating the effectiveness of language-based knowledge integration for action recognition.
Zero-Shot Action Recognition with Three-Stream Graph Convolutional Networks
Wu, Nan; Kawamoto, Kazuhiko. 2021. "Zero-Shot Action Recognition with Three-Stream Graph Convolutional Networks" Sensors 21, no. 11: 3793 [paper].
This work addresses zero-shot action recognition, where action classes are recognized without training examples. To overcome the limitations of RGB-based methods, we propose a three-stream graph convolutional network that integrates RGB video and skeleton data. By modeling temporal structure and skeletal motion, the proposed method achieves robust action recognition and outperforms existing approaches on multiple benchmark datasets.
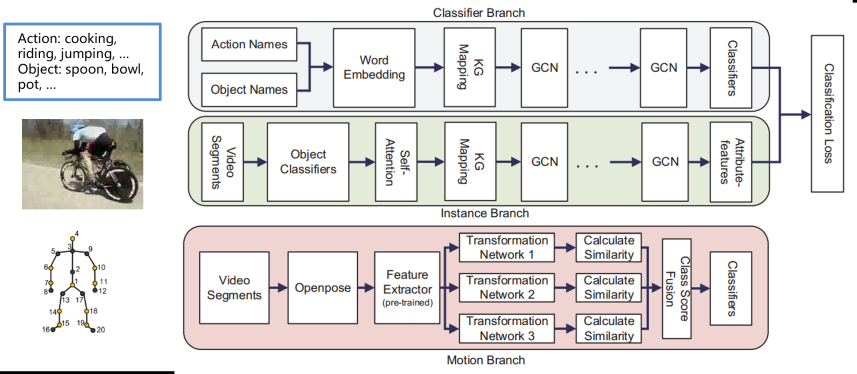
Improving Zero-Shot Action Recognition with Text-Based Instructions
Nan Wu, Hiroshi Kera, and Kazuhiko Kawamoto, Improving zero-shot action recognition using human instruction with text description, Applied Intelligence, vol.53, pp.24142–24156, 2023 [paper][SharedIt][arXix].
Nan Wu, Hiroshi Kera, and Kazuhiko Kawamoto, Zero-Shot Action Recognition with ChatGPT-based Instruction, Advanced Computational Intelligence and Intelligent Informatics, Communications in Computer and Information Science, vol. 1932, pp.18-28, 2024 [paper].
Zero-shot action recognition enables flexible recognition of unseen action classes but often suffers from limited accuracy. This research improves zero-shot performance by incorporating human knowledge in the form of text descriptions. Actions are represented using words or sentences, and recognition is performed by matching video features with textual representations. To further reduce manual effort, we introduce a ChatGPT-based instruction framework that automatically generates semantic action descriptions. This approach achieves high recognition accuracy without human annotation and outperforms existing automated methods. Experimental results show that the proposed framework is effective both as a standalone method and when combined with other action recognition models.
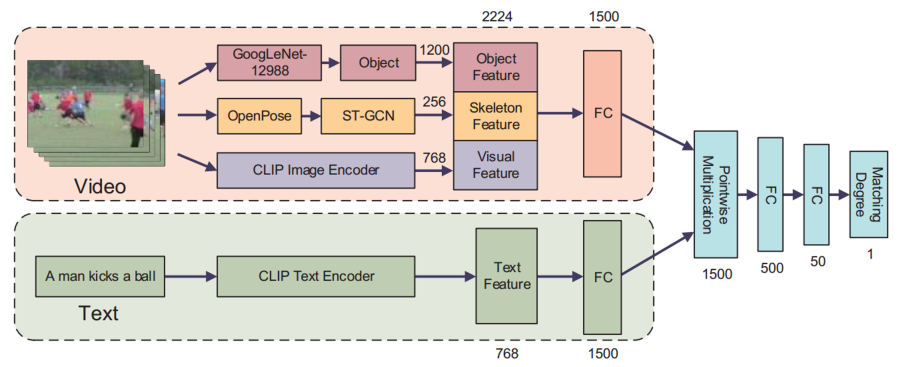
Skeleton-Based Action Recognition and Robustness Analysis
Skeleton data directly represents human joint structures and motions, making it robust to illumination and background variations. Our research focuses on skeleton-based action recognition using graph convolutional neural networks, where joints are modeled as graph nodes. By explicitly capturing joint relationships and structural constraints, we aim to achieve accurate and interpretable action representations.
We also investigate the robustness and vulnerabilities of skeleton-based models. We propose extremely low-dimensional adversarial attacks constrained to bone lengths, revealing previously unexplored weaknesses. Furthermore, we show that adversarial training can improve not only robustness but also classification accuracy. Using frequency-domain analysis based on graph and discrete Fourier transforms, we provide theoretical insights into model behavior and design guidelines for reliable action recognition systems.
Adversarial Attacks on Skeleton-Based Action Recognition
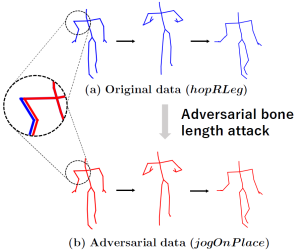
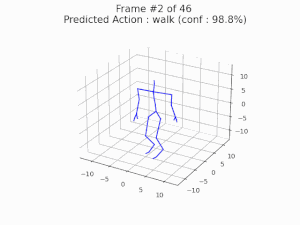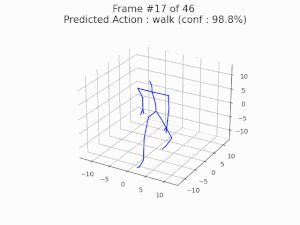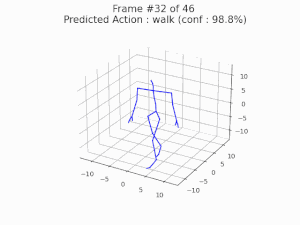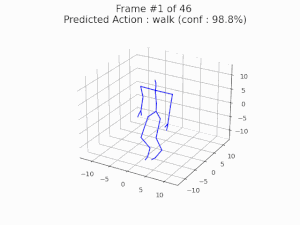
We investigate the robustness of skeleton-based action recognition models and show that effective adversarial attacks are possible even in extremely low-dimensional settings. By restricting perturbations to bone lengths, we demonstrate that models can be fooled with high success rates without any temporal manipulation. Furthermore, we reveal that adversarial training based on these attacks not only improves robustness but can also enhance classification accuracy on clean data.
Nariki Tanaka, Hiroshi Kera, and Kazuhiko Kawamoto, Adversarial Bone Length Attack on Action Recognition, AAAI 2022 [paper].
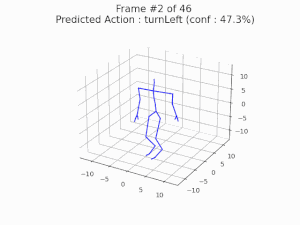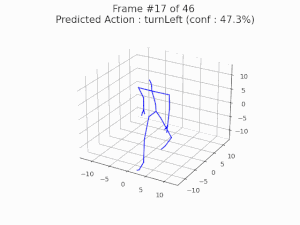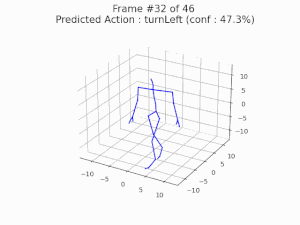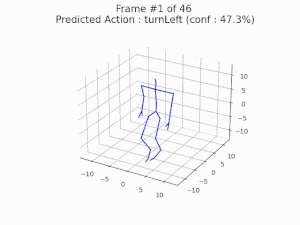
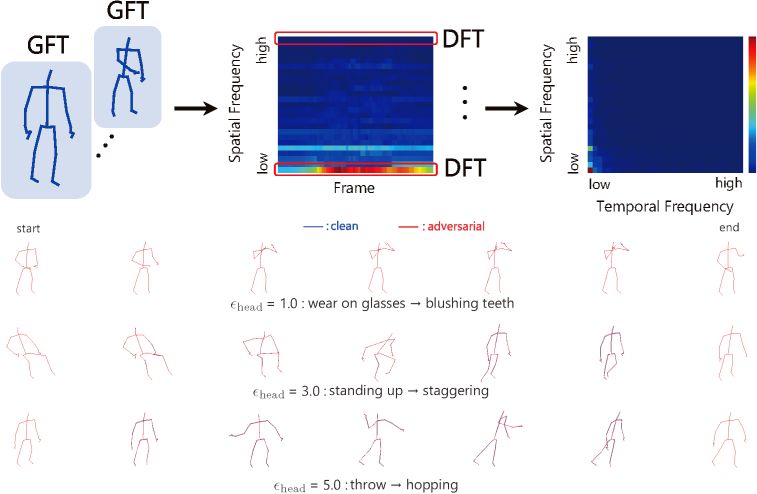
Robustness Analysis via Frequency-Domain Methods
Nariki Tanaka, Hiroshi Kera, Kazuhiko Kawamoto, Fourier analysis on robustness of graph convolutional neural networks for skeleton-based action recognition, Computer Vision and Image Understanding, Vol. 240, 2024 [paper][arXiv][GitHub].
This work analyzes the robustness and vulnerabilities of graph convolutional neural networks for skeleton-based action recognition from a frequency-domain perspective. By applying a joint Fourier transform that combines graph and discrete Fourier transforms, we show that adversarial training effectively improves robustness against both adversarial attacks and common input corruptions. At the same time, we identify limitations of frequency-based analysis in explaining robustness to partial skeleton occlusion, clarifying both the strengths and boundaries of Fourier-based approaches for understanding model behavior.
Egocentric Action Recognition
Egocentric action recognition requires advanced spatiotemporal understanding due to camera motion and complex object interactions. Our research proposes a multitask learning architecture that integrates visual appearance and optical flow features, enabling effective fusion of complementary cues for improved action recognition. In addition, we enhance generalization by generating training data through image synthesis that mimics real-world visual conditions. We also study interaction region detection, which focuses on objects directly involved in actions, allowing joint understanding of object recognition and action recognition.
Interaction Region Detection
Shinobu Takahashi and Kazuhiko Kawamoto, Object-Action Interaction Region Detection in Egocentric Videos, In Proc. of the 9th International Symposium on Computational Intelligence and Industrial Applications, 2020.
This work proposes a method for detecting object–action interaction regions in egocentric videos. Using a two-stream deep model that integrates object detection and action recognition, the approach enables learning with annotation on only a single frame per video. Experimental results show that jointly modeling both tasks achieves high interaction detection accuracy and improves action recognition performance.
Egocentric Action Recognition with Multitask Architectures
中村伊吹,川本一彦,岡本一志,一人称行動認識のための深層マルチタスクアーキテクチャ,電子情報通信学会論文誌D, Vol.J102-D, No.8, pp.506-513, 2019 [paper].
Shunpei Kobayashi and Kazuhiko Kawamoto, First-Person Activity Recognition by Deep Multi-task Network with Hand Segmentation, In Proc. of ISCIIA&ITCA, 2018.
This research proposes deep multitask learning architectures for action recognition from egocentric videos. By integrating visual appearance and optical flow features and incorporating skip connections, the models effectively exploit multiple visual cues. Experiments on real-world videos demonstrate that the proposed architectures achieve higher recognition accuracy than conventional approaches.
Deep Learning with Image Synthesis for Egocentric Action Recognition
Yuta Segawa, Kazuhiko Kawamoto, and Kazushi Okamoto, First-person reading activity recognition by deep learning with synthetically generated images, EURASIP Journal on Image and Video Processing, vol.2018-33, 13 pages, 2018 [paper].
This work addresses egocentric reading activity recognition by proposing a deep learning approach based on image synthesis. By combining computer-generated images with real background scenes, the method generates effective training data in scenarios where real data collection is difficult. Experimental results show that training with synthetic images significantly improves recognition performance compared to conventional approaches.
