First-Person Activity Recognition
Interaction Region Detection
We propose a deep model for detecting object–action interaction regions in egocentric videos. This task simultaneously includes object detection and action recognition, and we need to detect the only object involved in the action. We design a two–stream deep architecture that enables learning by annotating a single frame in a video clip to avoid the time-consuming annotation that assigns bounding boxes and object classes to every frame of the video clip. In this paper, we report the results of a comparative evaluation of four possible structures of the output layer of the two-stream architecture for multitask learning. Experimental results on the EPICKITCHENS dataset show that the structure of fusing object detection and action recognition provides better performance than the other structures.
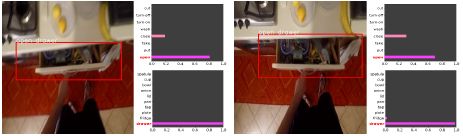
Shinobu Takahashi and Kazuhiko Kawamoto, Object-Action Interaction Region Detection in Egocentric Videos, In Proc. of the 9th International Symposium on Computational Intelligence and Industrial Applications, 2020.
Deep Multi-Task Learning Architecture
In this study, we propose a deep learning model architecture for action estimation from first-person videos. In first-person action recognition, it is generally difficult to collect datasets sufficient for adequately training deep learning models. Therefore, we introduce multitask learning to solve multiple tasks simultaneously. We implement two types of CNNs to extract image features and optical flow features. By introducing a skip structure and fusing deep feature maps, we construct a network where each CNN effectively works for its respective task. In our experiments on first-person action recognition using real videos, we demonstrate that using the proposed architecture improves recognition accuracy compared to previous research.
Ibuki Nakamura, Kazuhiko Kawamoto, and Kazushi Okamoto, Deep Multi-Task Learning Architecture for First-Person Activity Recognition, IEICE TRANSACTIONS on Information and Systems (Japanese Edition), Vol.J102-D, No.8, pp.506-513, 2019 (in Japaneses).
Shunpei Kobayashi and Kazuhiko Kawamoto, First-Person Activity Recognition by Deep Multi-task Network with Hand Segmentation, In Proc. of ISCIIA&ITCA, 5 pages, 2018.
Activity recognition by image synthesis
We propose a vision-based method for recognizing first-person reading activity with deep learning. For the success of deep learning, it is well known that a large amount of training data plays a vital role. Unlike image classification, there are fewer publicly available datasets for reading activity recognition, and the collection of book images might cause copyright trouble. In this paper, we develop a synthetic approach for generating positive training images. Our approach synthesizes computer-generated images and real background images. In experiments, we show that this synthesis is effective in combination with pre-trained deep convolutional neural networks and also our trained neural network outperforms other baselines.

Yuta Segawa, Kazuhiko Kawamoto, and Kazushi Okamoto, First-person reading activity recognition by deep learning with synthetically generated images, EURASIP Journal on Image and Video Processing, vol.2018-33, 13 pages, 2018 [paper].