Robust Reinforcement Learning for Control
In recent years, deep reinforcement learning has shown strong performance in complex control problems, including robot control. However, learned policies are often sensitive to inevitable variations in real-world environments, such as modeling errors, external disturbances, component degradation, and actuator failures. These vulnerabilities pose serious challenges for practical deployment, especially in terms of safety and reliability. This issue is particularly critical for high-degree-of-freedom and nonlinear systems such as legged robots, where even small errors can lead to falls or system failure. Therefore, a systematic understanding and design of robustness are essential.
In this line of research, we intentionally introduce perturbations—so-called adversarial perturbations—at different levels of the control system, including action signals, body morphology, and joint characteristics. By systematically exploring the conditions that cause performance degradation or instability, we aim to reveal the inherent vulnerabilities of learned policies and system structures. These studies are not intended to develop adversarial attacks themselves, but rather to use them as diagnostic tools for building safe and reliable control systems. By understanding the structure of such vulnerabilities, our work contributes to the development of robust learning methods, fault-tolerant control, and safety evaluation at the design stage. Overall, this research seeks to establish a foundation for applying reinforcement learning to real-world control problems, through both theoretical analysis and experimental validation, with a focus on robustness, safety, and reliability.
Application to Offline Reinforcement Learning
Offline reinforcement learning learns a policy only from previously collected data, without further interaction with the environment. Since it relies on stored trajectories of states, actions, and rewards, it can be used in settings where trial-and-error is unsafe or expensive, such as real robot systems. However, because learning is restricted to the given data, performance often becomes unstable when the policy faces situations or actions that were rarely or never observed during training. This vulnerability caused by data distribution bias is a central issue in offline reinforcement learning and motivates careful analysis of robustness.
Online Fine-Tuning for Offline Reinforcement Learning
Shingo Ayabe, Hiroshi Kera, Kazuhiko Kawamoto, Adversarial Fine-tuning in Offline-to-Online Reinforcement Learning for Robust Robot Control, arXiv:2510.13358, 2025 [arXiv].
This paper addresses the vulnerability of offline reinforcement learning, which is trained only on pre-collected data, to action deviations caused by actuator faults such as motor failures. After learning an initial policy through safe offline training, the proposed method performs additional online fine-tuning while intentionally injecting errors (adversarial perturbations) into the control actions. By automatically adjusting the probability of perturbation according to the learning progress, the method achieves improved robustness without sacrificing performance under normal conditions. Experiments on legged robot locomotion demonstrate the effectiveness of this approach. The figure below illustrates an overview of the proposed framework.
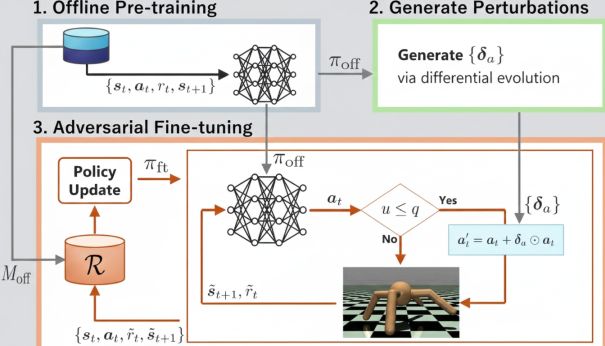
Robustness Evaluation of Offline Reinforcement Learning
Shingo Ayabe, Takuto Otomo, Hiroshi Kera, Kazuhiko Kawamoto, Robustness Evaluation of Offline Reinforcement Learning for Robot Control against Action Perturbations, International Journal of Advanced Robotic Systems, 22(4), 2025 [arXiv][paper].
This paper examines how vulnerable offline reinforcement learning, trained only on pre-collected data, becomes when errors or failures occur in joint torque control. Using a legged robot locomotion task, we introduce random perturbations as well as worst-case, adversarial action errors. The results show that offline-trained policies suffer much larger performance degradation than online-trained ones. Simply augmenting the training data with perturbed actions provides only limited improvement. These findings indicate that additional online learning is essential for adapting offline policies to real-world conditions. The figure below shows the robot used in the evaluation.

Application to Online Reinforcement Learning
Adversarial Attacks on the Body Shape of Legged Robots
This paper studies the robustness of legged robots trained by online reinforcement learning from the perspective of robot morphology. Instead of perturbing control actions, the method slightly modifies the robot’s body shape, such as link lengths and thicknesses, to search for shapes that significantly degrade walking performance. Evolutionary algorithms are used to identify adversarial body configurations that minimize locomotion rewards. Experiments show that breaking left–right symmetry and shifting the center of mass are major factors leading to falls. The results highlight that vulnerabilities can arise not only from control policies but also from physical design, and demonstrate the usefulness of adversarial analysis as a diagnostic tool in the robot design stage.

Adversarial Attacks on Joint Actuators of Legged Robots
Takuto Otomo, Hiroshi Kera, Kazuhiko Kawamoto, Adversarial joint attacks on legged robots, IEEE International Conference on Systems, Man, and Cybernetics (SMC), pp. 676-681, 2022 [paper][arXiv].
This paper investigates adversarial joint attacks that destabilize the walking of legged robots trained by deep reinforcement learning by adding small perturbations to joint actuator torque signals. The attacks are designed as black-box methods, requiring no access to the internal structure of the learned policy. Several search strategies—random search, evolutionary computation, and numerical gradient methods—are compared, and evolutionary computation is shown to be the most effective in finding strong perturbations. Experiments reveal that quadruped robots are vulnerable to perturbations at specific joints, whereas bipedal robots are relatively robust. These results suggest that adversarial joint attacks can serve as a practical tool for diagnosing walking stability and safety in advance.
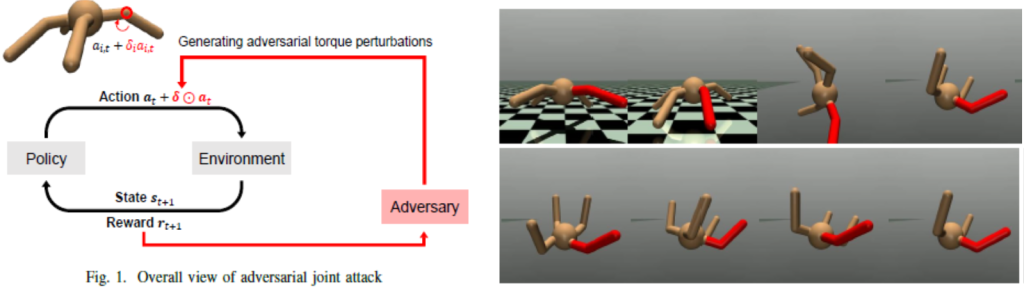
Fault-Tolerant Control via Dynamics Randomization
Wataru Okamoto, Hiroshi Kera, and Kazuhiko Kawamoto, Reinforcement Learning with Adaptive Curriculum Dynamics Randomization for Fault-Tolerant Robot Control, arXiv:2111.10005, 2021 [arXiv].
This paper proposes a reinforcement learning approach for legged robots that can continue walking even in the presence of actuator faults. The method combines dynamics randomization with an adaptive curriculum, allowing a single policy to handle both normal operation and fault conditions without explicitly detecting failures. In particular, a hard-to-easy curriculum—starting training under severe conditions and gradually easing them—is shown to be effective. Experiments demonstrate improved locomotion performance and fault tolerance compared to conventional methods, highlighting the benefit of curriculum-based dynamics randomization for robust robot control.