動画生成
映像データは監視,医療,エンタテインメント,ヒューマンインタフェースなど,多様な分野で急速に重要性を増している.しかし,実世界の動画データは高次元かつ時間的に複雑であり,大量のアノテーション付きデータを収集することは容易ではない.また,人の動作や表情,物体の相互作用といった本質的な要素は,単なる画素変化としてではなく,意味的・構造的な変化として理解される必要がある.このような背景から,本研究では,「動画をどのように分解し,どのような表現として獲得すべきか」,そして「限られたデータからでも柔軟で高品質な動画生成を実現できるか」という根本的な問いに基づき,動画生成研究に取り組んでいる.静的要素と動的要素の分離,未知クラスへの汎化,画像から動画への変換,さらには映像から音を生成するマルチモーダル生成などを通じて,動画の本質的構造を捉える生成モデルの構築を目指している.
ビデオデータの解きほぐし
Haga, Takeshi, Hiroshi Kera, and Kazuhiko Kawamoto, Sequential Variational Autoencoder with Adversarial Classifier for Video Disentanglement, Sensors 23, no. 5: 2515, 2023 [paper].
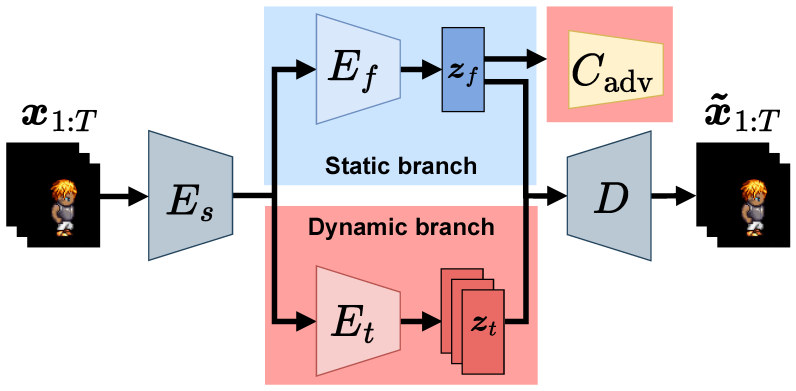
本論文では,ビデオの分離に使用可能な表現学習手法として,動画のための逐次的変分オートエンコーダーを提案している.提案手法は,ビデオから静的特徴と動的特徴を別々に抽出することを目的としており,2ストリームアーキテクチャを採用することで,ビデオ分離に対する帰納的バイアスを導入している.しかし,予備実験により,静的特徴が動的特徴を含んでしまう問題や,潜在空間における動的特徴が十分に識別的でない問題が確認された.これらの課題に対し,本研究では教師あり学習を用いた敵対的分類器を2ストリームアーキテクチャに導入した.この強い教師付き帰納的バイアスにより,動的特徴が静的特徴から明確に分離され,識別的な動的表現の獲得が可能となった.SpritesおよびMUGデータセットを用いた実験により,提案手法の有効性を質的・量的に示している.
フロー転写による画像アニメーション
Kazuma Kurisaki and Kazuhiko Kawamoto, Animating Cloud Images With Flow Style Transfer, IEEE Access, Vol.9, pp.3269-3277, 2021 [paper][GitHub].
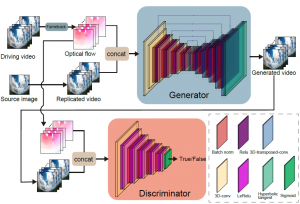
本論文では,静止画像を動画へと変換する,すなわち画像をアニメーション化するための深層学習モデルの開発を行っている.提案手法では,静止画像とは別に用意した動画から動き情報(光フロー)を抽出し,その動きを静止画像へ転写することで動画生成を実現する.このアプローチにより,元の静止画像の外観を保持したまま,自然な動きを付与することが可能となる.画像内容と動き情報を分離して扱うことで,柔軟かつ制御性の高い動画生成を目指している.
![]()
Food ASMRビデオからの食感音の生成
Kodai Uchiyama and Kazuhiko Kawamoto, Audio-Visual Model for Generating Eating Sounds Using Food ASMR Videos, IEEE Access, Vol.9, pp.50106-50111, 2021 [paper][GitHub].
本論文では,無音の食事ビデオから食品の食感音を生成する音声・映像統合モデルを提案している.提案モデルは,検出された顔領域の視覚的特徴を入力とし,視覚ストリームと時間的に整合したスペクトログラムを出力する深層学習モデルである.直接的に波形を生成することは困難であるため,予測された振幅スペクトログラムから位相を回復するためにグリフィン・リムアルゴリズムを用い,逆短時間フーリエ変換により音声波形を生成した.さらに,例に基づく合成手法を併用することで,より自然な音生成を実現している.ASMRビデオを含む独自データセットを構築し,時間同期性および主観評価実験により,生成音が高い現実感を持つことを確認している.
深層学習による構成的ゼロショットビデオ生成
Shun Kimura and Kazuhiko Kawamoto, "Conditional Motion and Content Decomposed GAN for Zero-Short Video Generation," In Proc. of the 7th International Workshop on Advanced Computational Intelligence and Intelligent Informatics, 2021 [arXix].
本論文では,ゼロショット動画生成のための条件付き生成敵対ネットワークモデルを提案している.特に,クラスが部分的に欠損した学習データのみを用いて,未知クラスの動画を生成する構成的ゼロショット条件付き生成の設定を対象とする.この課題の鍵となるのは,GANの潜在空間において,動きと内容を分離した表現を学習することである.本研究では,動きと内容を分解する画像生成GANと条件付きGANを基盤としたモデルを構築し,より良好な分離表現の獲得と高品質な動画生成を実現した.Weizmann行動データベースおよびMUG表情データベースを用いた実験により,提案モデルの有効性を実証している.

GANによるデプス推定とカラー変換を用いたビデオ生成
Y. Nakahira and K. Kawamoto, DCVGAN: Depth Conditional Video Generation, IEEE International Conference on Image Processing (ICIP), pp. 749-753, 2019 [paper][GitHub].
Y. Nakahira and K. Kawamoto, Generative adversarial networks for generating RGB-D videos, Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), pp. 1276-1281, 2018 [paper].
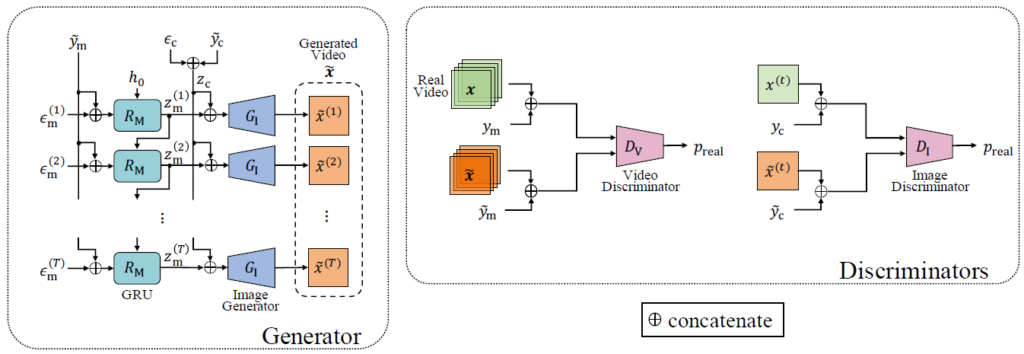
本論文では,カラー映像に加えて奥行き情報を利用することで,高品質な動画生成を実現するGANアーキテクチャを提案している.従来の多くの動画生成手法はカラー情報のみに基づいて学習を行っていたが,シーンのダイナミクスを正確に捉えるためには三次元的な幾何情報が重要である.提案アーキテクチャでは,生成器の前段で奥行き映像を生成し,後段で奥行きから色への変換を行う構成を採用している.奥行き情報に基づいてシーンの動きをモデル化することで,従来手法よりも種類と品質の両面で優れた映像生成を実現した.顔表情およびハンドジェスチャーデータセットを用いた評価により,本手法の有効性を示している.