行動認識
人の行動を映像や骨格データから理解する行動認識は,ヒューマンインタフェース,ロボティクス,監視,医療支援など,多様な応用を持つ基盤技術である.一方で,行動認識には,環境変動に対する頑健性の不足,未知の行動クラスへの一般化性能,および深層学習モデルの信頼性と解釈性といった本質的な課題が存在する.
本研究では,これらの課題に対し,スケルトンデータや一人称視点映像といった多様なモダリティの統合,ゼロショット学習やマルチタスク学習による汎化性能の向上,敵対的攻撃や周波数解析を通じたロバスト性の解明,および言語情報を介した人間知識の導入に取り組んでいる.これにより,実環境において安定して機能する行動認識モデルの確立を目指している.
ゼロショット・言語活用による行動認識
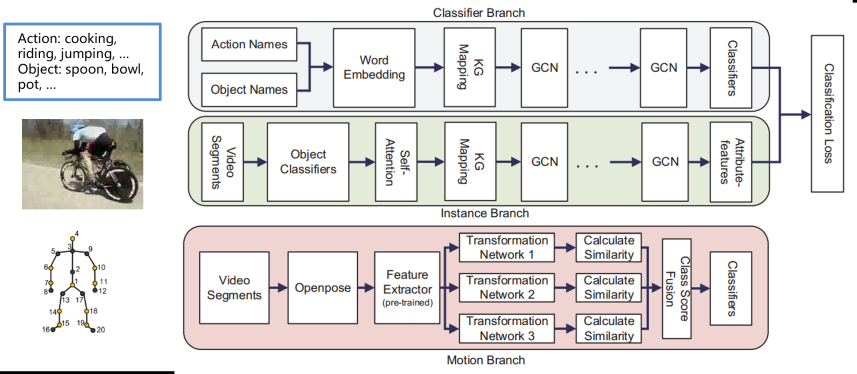
本研究では,未知の行動クラスに対しても認識可能なゼロショット行動認識に取り組んでいる.従来手法の多くはRGB映像のフレーム単位の特徴に依存しており,環境変動や時系列構造の扱いに課題があった.これに対し,本研究では,RGB映像とスケルトンデータを統合するマルチストリームグラフ畳み込みネットワークを提案し,環境に対して頑健で時系列情報を考慮した行動認識を実現している.また,行動を単語や文章で記述する画像―言語アプローチを導入し,人間の指示や知識を活用することでゼロショット設定における認識精度の向上を達成している.さらに,ChatGPTを用いて行動の意味的特徴を自動生成することで,人手による介入を最小限に抑えつつ高い性能を維持する手法を提案している.
スケルトンデータを用いた3ストリームグラフ畳み込みニューラルネットワーク
Wu, Nan; Kawamoto, Kazuhiko. 2021. "Zero-Shot Action Recognition with Three-Stream Graph Convolutional Networks" Sensors 21, no. 11: 3793 [paper].
行動認識では高精度化のために大規模データセットが用いられることが多いが,アノテーションコストが大きな課題となる.そこで,本研究では,学習時に行動クラスの例を必要としないゼロショット行動認識に取り組んでいる.従来手法はRGB映像のフレーム単位の特徴に依存し,照明や背景の影響を受けやすく,時系列構造を十分に扱えないという問題があった.本研究では,RGBデータとスケルトンデータを統合する3ストリームのグラフ畳み込みネットワークを提案し,環境変動に頑健で時系列情報を考慮した行動認識を実現している.複数のデータセットによる実験により,提案手法が従来手法より高い認識精度を達成することを示している.
テキスト記述を用いた画像-言語アプローチによる精度向上
Nan Wu, Hiroshi Kera, and Kazuhiko Kawamoto, Improving zero-shot action recognition using human instruction with text description, Applied Intelligence, vol.53, pp.24142–24156, 2023 [paper][SharedIt][arXix].
Nan Wu, Hiroshi Kera, and Kazuhiko Kawamoto, Zero-Shot Action Recognition with ChatGPT-based Instruction, Advanced Computational Intelligence and Intelligent Informatics, Communications in Computer and Information Science, vol. 1932, pp.18-28, 2024 [paper].
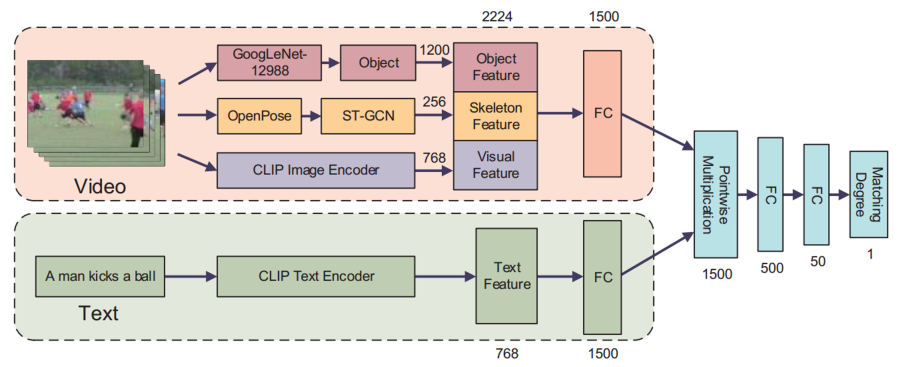
ゼロショット行動認識は,学習時にトレーニング例を必要とせず,新しい行動クラスを柔軟に認識できる点で注目されているが,認識精度の低さが実用化の課題となっている.本研究では,人間の知識をテキスト記述として導入することで,ゼロショット行動認識の性能向上を図っている.具体的には,行動を単語や文章で表現し,映像とテキスト特徴の対応関係を用いて行動を推定する枠組みを提案している.さらに,手動による記述コストを削減するため,ChatGPTを用いて行動の意味的特徴を自動生成する手法を導入している.このアプローチにより,人手による注釈を必要とせずに高精度な認識を実現し,既存の自動化手法を上回る性能を達成している.実験結果から,提案手法は単独でも有効であり,他の行動認識モデルと組み合わせることでさらなる精度向上が可能であることを示している.
スケルトンベース行動認識とロバスト性解析
スケルトンデータは,人の関節構造と運動を直接表現できるため,照明や背景の影響を受けにくく,行動認識に適した表現である.本グループでは,関節をノードとするグラフ構造に基づき,グラフ畳み込みニューラルネットワークを用いたスケルトンベース行動認識を研究している.関節間の関係性や構造的制約を明示的にモデル化することで,高精度かつ解釈性の高い行動表現の獲得を目指している.
さらに,スケルトン構造に着目することで,行動認識モデルのロバスト性と脆弱性の解析にも取り組んでいる.骨の長さに限定した極めて低次元な敵対的攻撃を提案し,従来想定されていなかった脆弱性を明らかにするとともに,敵対的学習が頑健性だけでなく分類精度の向上にも寄与する現象を示している.加えて,グラフフーリエ変換と離散フーリエ変換を用いた周波数解析により,モデルの挙動を理論的に解析し,信頼性の高い行動認識モデルの設計指針を提供している.
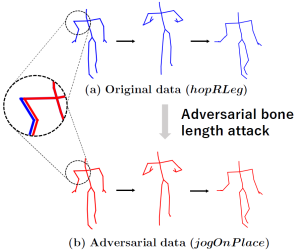
骨格ベース行動認識への敵対的攻撃
スケルトンに基づく行動認識モデルのロバスト性に着目し,極めて低次元な設定においても有効な敵対的攻撃が可能であることを示している.骨の長さに限定した摂動により,時間的操作を用いずにモデルを高い成功率で欺けることを実証した.さらに,この攻撃を用いた敵対的学習が,ロバスト性の向上だけでなく,元データに対する認識精度の向上にも寄与することを明らかにしている.
Nariki Tanaka, Hiroshi Kera, and Kazuhiko Kawamoto, Adversarial Bone Length Attack on Action Recognition, AAAI 2022 [paper].
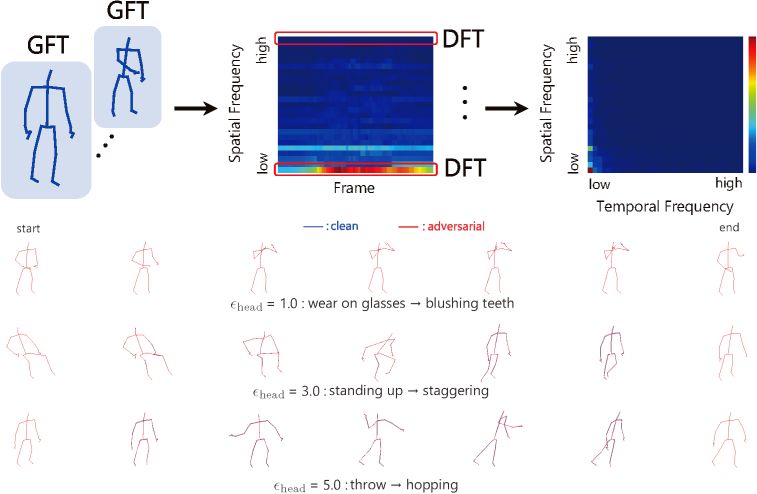
周波数解析を用いたロバスト性解析
Nariki Tanaka, Hiroshi Kera, Kazuhiko Kawamoto, Fourier analysis on robustness of graph convolutional neural networks for skeleton-based action recognition, Computer Vision and Image Understanding, Vol. 240, 2024 [paper][arXiv][GitHub].
骨格ベース行動認識におけるグラフ畳み込みニューラルネットワークのロバスト性と脆弱性を,フーリエ解析の観点から解析している.グラフフーリエ変換と離散フーリエ変換を組み合わせた共同フーリエ変換を用いることで,敵対的学習が敵対的攻撃および一般的な入力破損に対するロバスト性を効果的に向上させることを示している.一方で,骨格の部分遮蔽に対しては説明が困難であることを明らかにし,周波数解析に基づく手法の有効性と限界の両方を示している.
一人称視点行動認識とマルチモーダル学習
一人称視点映像による行動認識は,視点の揺れや複雑な物体操作を含むため,高度な時空間理解が求められる.本グループでは,画像特徴とオプティカルフロー特徴を統合するマルチタスク学習アーキテクチャを提案し,視覚的手がかりを効果的に融合することで行動認識性能の向上を図っている.さらに,画像合成によるトレーニングデータ生成を通じて,実環境に近い視覚条件を再現し,深層学習モデルの汎化性能を高めている.加えて,行動に直接関与する物体領域に着目したインタラクション領域検出により,物体認識と行動認識を統合した理解を実現している.
インタラクション領域検出
Shinobu Takahashi and Kazuhiko Kawamoto, Object-Action Interaction Region Detection in Egocentric Videos, In Proc. of the 9th International Symposium on Computational Intelligence and Industrial Applications, 2020.
一人称視点映像において,行動に関与する物体との相互作用領域を検出する手法を提案している.物体検出と行動認識を統合した2ストリームの深層モデルを用い,動画中の1フレームのみの注釈で学習を可能としている.実験により,両タスクを融合する構造が,高い検出性能と行動認識精度を実現することを示している.
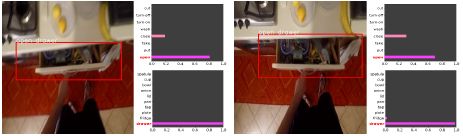
マルチタスクアーキテクチャによる一人称行動認識
中村伊吹,川本一彦,岡本一志,一人称行動認識のための深層マルチタスクアーキテクチャ,電子情報通信学会論文誌D, Vol.J102-D, No.8, pp.506-513, 2019 [paper].
Shunpei Kobayashi and Kazuhiko Kawamoto, First-Person Activity Recognition by Deep Multi-task Network with Hand Segmentation, In Proc. of ISCIIA&ITCA, 2018.
一人称視点映像からの行動認識に対し,マルチタスク学習を用いた深層学習アーキテクチャを提案している.画像特徴とオプティカルフロー特徴を統合し,スキップ構造を導入することで,複数の視覚的手がかりを効果的に活用する.実動画による実験から,提案手法が従来手法より高い認識精度を達成することを示している.
一人称視点行動認識のための画像合成による深層学習
Yuta Segawa, Kazuhiko Kawamoto, and Kazushi Okamoto, First-person reading activity recognition by deep learning with synthetically generated images, EURASIP Journal on Image and Video Processing, vol.2018-33, 13 pages, 2018 [paper].
一人者視点における読書行動認識を対象とし,画像合成を用いた深層学習手法を提案している.コンピュータ生成画像と実背景画像を合成することで,実データ収集が困難な状況でも有効な学習データを生成する.実験により,合成データを用いた学習が,従来手法より高い認識性能を達成することを示している.
