深層学習モデルの加減算による知識転移
近年の深層学習モデルは高い性能を示す一方で,その学習には膨大な計算資源とエネルギーを要し,計算コストや環境負荷の観点から大きな課題となっている.このような状況において,一度学習したモデルを再学習することなく,いかに効率的に再利用・適応させるかは,深層学習研究における重要な問題である.本研究では,モデル内部の知識をパラメータ空間上の差分として抽出し,それらを加減算・再重み付けによって操作する枠組みを探究する.この枠組みでは,大規模な追加学習や勾配計算を必要とせず,既存モデルの差分操作のみでタスク適応,知識統合,モデル間転移を実現できるため,計算量およびエネルギー消費の両面で高い効率性を有する.本研究では,このような知識操作としての深層学習を理論的・実証的に検討している.
![]()
継続学習における知識更新
Takuma Fukuda, Hiroshi Kera, Kazuhiko Kawamoto, Adapter Merging with Centroid Prototype Mapping for Scalable Class-Incremental Learning, CVPR, pp. 4884-4893, 2025 [arXiv][paper][GitHub].
本論文では,継続学習の一種であるクラス増分学習(学習の進行に伴って認識すべきクラスが段階的に追加される設定)を対象とする.クラス増分学習では,新しいクラスを学習するたびにモデルを拡張すると,計算コストやモデルサイズが増大するという課題がある.本研究では,各タスクで学習した小規模な追加モジュール(アダプタ)を統合するAdapter Mergingと,各クラスの特徴を代表点(重心)として管理するCentroid Prototype Mapping を組み合わせた手法を提案する.これにより,モデルを大きく増やすことなく新規クラスを追加でき,過去クラスの性能を維持したまま,推論時の計算量増加を抑えたスケーラブルなクラス増分学習を実現する.下図は,提案手法の概要である.
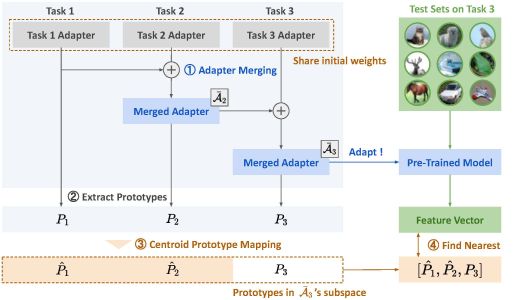
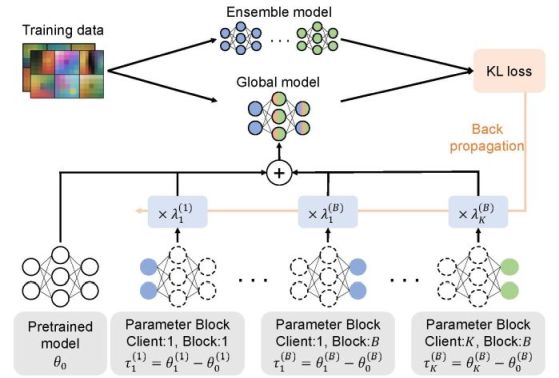
連合学習における知識統合
Shunsei Koshibuchi, Hiroshi Kera, Kazuhiko Kawamoto, OFASD: One-Shot Federated Anisotropic Scaling Distillation, LIMIT Workshop in ICCV 2025 [web][paper].
本研究は,連合学習と呼ばれる,複数のクライアントがデータを共有せずに個別に学習したモデルを統合する分散学習の枠組みを対象とする.特に,各クライアントが学習結果を一度だけ送信するワンショット連合学習に対して,複数クライアントの学習結果をモデル差分の加重和として統合する手法を提案する.各クライアントのモデル差分に対して異方的スケーリング係数を最適化することで,非IID環境下においても性能低下を抑えた知識統合を実現する.追加の通信や再学習を必要とせず,モデルの加減算のみで効率的に統合できる点が本手法の特徴である.
異なるデータセットで事前訓練したモデル間の知識転移
Kazuhiko Kawamoto, Atsuhiro Endo, Hiroshi Kera, Cross-Model Transfer of Task Vectors via Few-Shot Orthogonal Alignment, arXiv:2505.12021, 2025 [arXiv][GitHub].
本研究では,タスク固有の学習結果をモデルパラメータの差分(タスクベクトル)として表現し,異なる事前学習モデル間でもその加減算を可能にする転移手法を提案する.従来のタスク算術は同一初期化を前提としていたが,本手法では少数データを用いて直交変換を学習し,パラメータ空間を整合させる.これにより,モデル本体を再学習することなく,他モデルへタスク知識を転移できることを示した.