Knowledge Transfer via Model Arithmetic in Deep Learning
Recent deep learning models achieve impressive performance, but their training requires enormous computational resources and energy, raising serious concerns about cost and environmental impact. In this context, a key challenge in deep learning research is how to reuse and adapt trained models efficiently without retraining them from scratch.
In this research, we explore a framework that represents a model’s internal knowledge as parameter-space differences and manipulates them through simple operations such as addition, subtraction, and reweighting. This approach enables task adaptation, knowledge integration, and cross-model transfer using only arithmetic operations on existing models, without large-scale retraining or gradient-based optimization. As a result, it offers high efficiency in terms of both computational cost and energy consumption. We study this paradigm of deep learning as knowledge manipulation from both theoretical and empirical perspectives.
![]()
Knowledge Updating in Continual Learning
Takuma Fukuda, Hiroshi Kera, Kazuhiko Kawamoto, Adapter Merging with Centroid Prototype Mapping for Scalable Class-Incremental Learning, CVPR, pp. 4884-4893, 2025 [arXiv][paper][GitHub].
This paper focuses on class-incremental learning, a form of continual learning in which new classes are introduced sequentially over time. A key challenge in this setting is that naively expanding the model for each new class leads to increased computational cost and model size. To address this issue, we propose a method that combines Adapter Merging, which integrates small task-specific modules learned for each task, with Centroid Prototype Mapping, which represents each class by a compact centroid of its feature distribution. By merging adapters and managing classes through centroids, the proposed approach enables the addition of new classes without significantly increasing model size, while preserving performance on previously learned classes. This results in a scalable class-incremental learning framework with efficient inference. The figure below illustrates an overview of the proposed method.
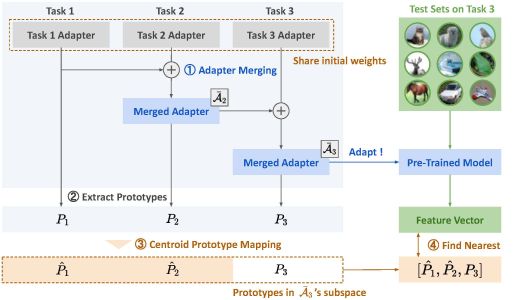
Knowledge Integration in Federated Learning
Shunsei Koshibuchi, Hiroshi Kera, Kazuhiko Kawamoto, OFASD: One-Shot Federated Anisotropic Scaling Distillation, LIMIT Workshop in ICCV 2025 [web][paper].
This work focuses on federated learning, a distributed learning framework in which multiple clients train models locally without sharing their data, and only the learned models are aggregated. In particular, we address one-shot federated learning, where each client communicates its training result only once. We propose a method that integrates the models from multiple clients as a weighted sum of model differences. By optimizing anisotropic scaling coefficients for each client’s model difference, the proposed approach achieves robust knowledge integration even under non-IID data distributions. Notably, the method requires no additional communication rounds or retraining, and performs model integration efficiently using only simple arithmetic operations on model parameters.
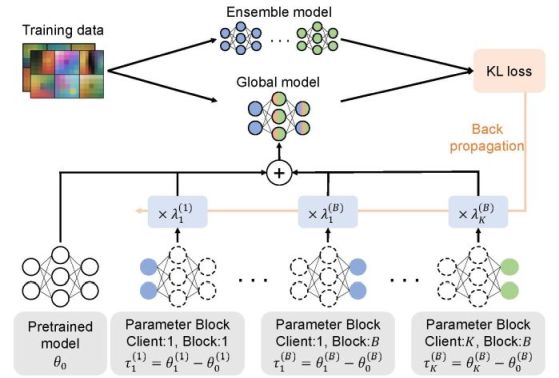
Knowledge Transfer Across Models Pretrained on Different Datasets
Kazuhiko Kawamoto, Atsuhiro Endo, Hiroshi Kera, Cross-Model Transfer of Task Vectors via Few-Shot Orthogonal Alignment, arXiv:2505.12021, 2025 [arXiv][GitHub].
This work proposes a transfer method that represents task-specific learning outcomes as parameter differences, referred to as task vectors, and enables their addition and subtraction across models pretrained on different datasets. While conventional task arithmetic assumes a shared initialization, the proposed approach learns an orthogonal alignment between parameter spaces using only a small amount of data. This alignment makes it possible to reuse and transfer task knowledge from one pretrained model to another without retraining the target model, demonstrating an efficient mechanism for cross-model knowledge transfer.