制御のためのロバスト強化学習
近年,深層強化学習はロボット制御をはじめとする複雑な制御問題において高い性能を示している.一方で,学習された方策は,モデル化誤差,外乱,部品劣化,故障といった現実環境に不可避な変動に対して脆弱であり,安全性や信頼性の観点から実応用には大きな課題が残されている.特に,脚ロボットのような多自由度・非線形システムでは,わずかな誤差が転倒や機能停止に直結するため,ロバスト性の体系的理解と設計が不可欠である.
本研究では,行動信号,身体形状,関節特性など,制御系の異なる階層に対して意図的な摂動(敵対的摂動)を与え,性能劣化や不安定化を引き起こす条件を系統的に探索することで,学習方策やシステム構造に内在する脆弱性を明らかにする.これらの研究は,敵対的攻撃そのものを目的とするものではなく,安全で信頼できる制御系を構築するための「診断手段」として位置づけられる.脆弱性の構造を理解することで,ロバストな学習手法,耐故障制御,設計段階での安全性評価へと発展させることが可能となる.本研究群は,強化学習を現実世界の制御問題へ適用するための基礎として,ロバスト性・安全性・信頼性を理論と実験の両面から探究することを目指している.
オフライン強化学習への適用
オフライン強化学習とは,環境と新たに相互作用することなく,過去に収集されたデータのみを用いて方策を学習する強化学習手法である.あらかじめ蓄積された状態・行動・報酬の履歴データを用いて学習を行うため,実機ロボットのように試行錯誤が危険または高コストな場面でも利用できる利点がある.一方で,学習時に観測されなかった状況や行動に対しては性能が不安定になりやすく,データ分布の偏りに起因する脆弱性が課題として知られている.
オフライン強化学習に対するオンラインファインチューニング
Shingo Ayabe, Hiroshi Kera, Kazuhiko Kawamoto, Adversarial Fine-tuning in Offline-to-Online Reinforcement Learning for Robust Robot Control, arXiv:2510.13358, 2025 [arXiv].
本論文は,事前に収集したデータのみで学習するオフライン強化学習が,モータ故障などによる行動のずれに対して脆弱であるという問題を扱っている.安全なオフライン学習で初期方策を獲得した後,オンライン環境で意図的に誤差(敵対的摂動)を加えながら追加学習を行う手法を提案した.さらに,学習状況に応じて誤差の付与確率を自動調整する仕組みにより,通常時の性能を維持しつつ高い頑健性を実現できることを,脚ロボットの歩行実験により示している.下図は,提案手法の全体概要図である.
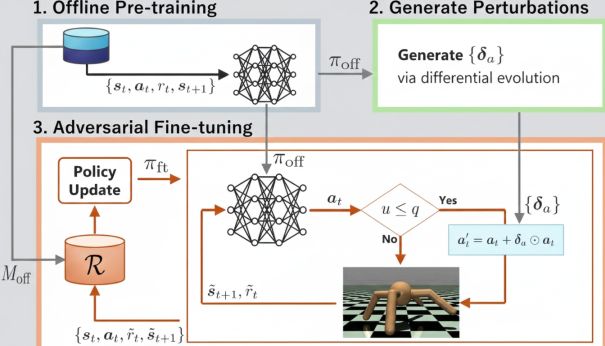
オフライン強化学習に対するロバスト性評価
Shingo Ayabe, Takuto Otomo, Hiroshi Kera, Kazuhiko Kawamoto, Robustness Evaluation of Offline Reinforcement Learning for Robot Control against Action Perturbations, International Journal of Advanced Robotic Systems, 22(4), 2025 [arXiv][paper].
本論文は,事前に収集したデータのみを用いて学習を行うオフライン強化学習が,ロボットの関節トルクに誤差や故障が生じた場合にどの程度脆弱となるかを検証するものである.脚ロボットの歩行タスクにおいて,ランダムな誤差や最悪条件を想定した攻撃的な誤差を付与した結果,オフライン学習はオンライン学習と比較して性能低下が大きいことが確認された.また,誤差を加えたデータを用いた単純な学習では改善効果が限定的であり,実環境への適応にはオンラインでの追加学習が重要であることを示している.下図は,検証にもちいたロボットである.

オンライン強化学習への適用
歩行ロボットの体型への敵対的攻撃
本論文は、深層強化学習で歩行を獲得した脚ロボットに対し、身体形状そのものをわずかに変化させることで歩行性能を著しく低下させる「敵対的身体形状」を探索する手法を提案している。部位の長さや太さへの微小な変化を進化計算により探索し、歩行報酬が最小となる形状を特定する。実験の結果、左右対称性の破壊や重心移動が転倒の主因であることが示され、ロボット設計段階での脆弱性診断に有用であることを明らかにしている。

歩行ロボットの関節アクチュエータへの敵対的攻撃
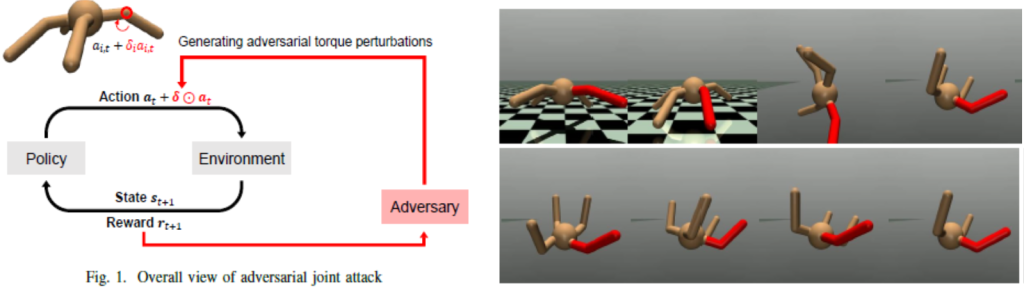
Takuto Otomo, Hiroshi Kera, Kazuhiko Kawamoto, Adversarial joint attacks on legged robots, IEEE International Conference on Systems, Man, and Cybernetics (SMC), pp. 676-681, 2022 [paper][arXiv].
本論文は、深層強化学習で歩行を獲得した脚ロボットに対し、関節アクチュエータのトルク信号へ微小な摂動を加えることで歩行を不安定化させる「敵対的関節攻撃」を検討している。学習済みモデルの内部にアクセスしないブラックボックス攻撃として、ランダム探索、進化計算、数値勾配法を比較し、進化計算が最も効率的に強い攻撃を発見できることを示した。四脚ロボットは特定関節への摂動に脆弱である一方、二脚ロボットは比較的頑健であることを明らかにし、歩行安全性の事前診断への応用可能性を示している。
ダイナミクスランダム化による耐故障制御
Wataru Okamoto, Hiroshi Kera, and Kazuhiko Kawamoto, Reinforcement Learning with Adaptive Curriculum Dynamics Randomization for Fault-Tolerant Robot Control, arXiv:2111.10005, 2021 [arXiv].
本論文は,アクチュエータ故障に対しても歩行を継続可能な脚ロボット制御を実現するため,適応的カリキュラム学習と動力学ランダム化を組み合わせた強化学習手法を提案する.故障状態を明示的に検知することなく,単一の方策で正常時と故障時の双方に対応できる点に特徴がある.特に,困難な条件から学習を開始する hard-to-easy カリキュラムが有効であることを示し,従来手法より高い歩行性能と耐故障性を実験的に確認している.